Variation of Data
One simple way to measure the variation of a data set is its range.
Example :
Consider the set of values: .
The highest value of the data set is and the lowest is . So, the range of the data set is
But that doesn't tell the whole story. Sometimes, we are also interested in how clustered or spread out the data is.
Consider another set of data .
The two sets have almost the same range, but the distributions have different shapes.
If you draw a line plot of the two, it will look like this:
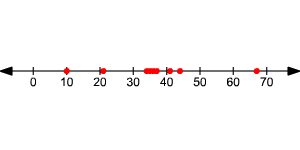
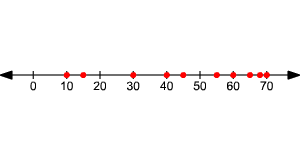
In the first data set, the data is clustered around the median, .
In the second data set, the data is more spread out, with a little cluster near the top of the range.
In a set of data, the quartiles are the values that divide the data into four equal parts. The median of a set of data separates the set in half.
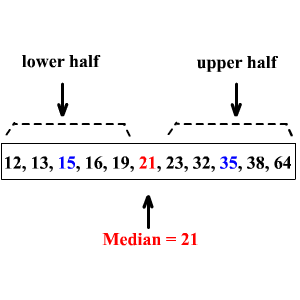
The median of the lower half of a set of data is the lower quartile (LQ) or .
The median of the upper half of a set of data is the upper quartile (UQ) or .
Here, and
The upper and lower quartiles can be used to find another measure of variation call the interquartile range.
The interquartile range is the range of the middle half of a set of data. It is the difference between the upper quartile and the lower quartile.
Interquartile range =
In the above example, the interquartile range is .
Data points that are more than times the value of the interquartile range beyond the quartiles are called outliers.
- Washington Bar Exam Test Prep
- WEST-E Courses & Classes
- NBDE Test Prep
- Nevada Bar Exam Test Prep
- Middle School Social Studies Tutors
- CLEP College Algebra Test Prep
- IB Further Mathematics HL Tutors
- AP Calculus AB Tutors
- Oregon Bar Exam Test Prep
- Series 9 Courses & Classes
- Series 39 Courses & Classes
- Speech Science Tutors
- NBE - National Board Exam for Funeral Services Test Prep
- Swedish Tutors
- TABE Tutors
- SSAT- Upper Level Tutors
- SAT Subject Tests Courses & Classes
- Series 7 Tutors
- Applied Philosophy Tutors
- AU-M - Associate in Commercial Underwriting-Management Test Prep