Standard Operations & Algorithms - AP Computer Science A
Card 0 of 319
What's the best way to traverse this list in Swift (iOS)?
var list: \[Int\] = \[0, 1, 2, 3, 4, 5\]
What's the best way to traverse this list in Swift (iOS)?
var list: \[Int\] = \[0, 1, 2, 3, 4, 5\]
The correct answer is the best way because it uses Swift's built in "in" operator. In this case, "in" will convert the thing that comes after "in" (so in this case, list) into a range operator. Essentially it will say "i in range(list.count)." This is why the other answer choice that uses "in" is incorrect in terms of the "best" way to traverse a list of integers in Swift.
The correct answer is the best way because it uses Swift's built in "in" operator. In this case, "in" will convert the thing that comes after "in" (so in this case, list) into a range operator. Essentially it will say "i in range(list.count)." This is why the other answer choice that uses "in" is incorrect in terms of the "best" way to traverse a list of integers in Swift.
Compare your answer with the correct one above
Of the choices below, what is the most efficient sorting algorithm for an unordered list where the size of the list is an odd number and the size of the list is finite?
Of the choices below, what is the most efficient sorting algorithm for an unordered list where the size of the list is an odd number and the size of the list is finite?
Mergesort is the most efficient among the choices. Both selection sort and insertion sort use O(N2) time. Bubble Sort may seem like a good answer but uses O(N2) time most of the time and can be adapted to use O(N) time however only when the list is nearly sorted, so it's a gamble. Mergesort always uses O(NlogN) time and thus is always the most efficient among the four choices.
Mergesort is the most efficient among the choices. Both selection sort and insertion sort use O(N2) time. Bubble Sort may seem like a good answer but uses O(N2) time most of the time and can be adapted to use O(N) time however only when the list is nearly sorted, so it's a gamble. Mergesort always uses O(NlogN) time and thus is always the most efficient among the four choices.
Compare your answer with the correct one above
What is the worst-case run-time of selection sort (in Big-O notation?)
What is the worst-case run-time of selection sort (in Big-O notation?)
Selection sort is comprised of outer and inner for loops that swap elements of the unsorted array into a sorted array. The largest possible number of times each loop can run is the number of elements in the array. Thus, the worst possible run time is ") .
.
Selection sort is comprised of outer and inner for loops that swap elements of the unsorted array into a sorted array. The largest possible number of times each loop can run is the number of elements in the array. Thus, the worst possible run time is
Compare your answer with the correct one above
True or False.
Selection sort is quicker than MergeSort.
True or False.
Selection sort is quicker than MergeSort.
MergeSort is has a running time of O(N). Selection sort has a running time of O(N2). Selection sort has O(N2) comparisons due to the swap in the algorithm.
MergeSort is has a running time of O(N). Selection sort has a running time of O(N2). Selection sort has O(N2) comparisons due to the swap in the algorithm.
Compare your answer with the correct one above
The function recur is defined as follows:
public int recur(int x)
{
if (x <= 1)
{
return 1;
}
else
{
return x + recur(x/2);
}
}
How many times is recur called in the following declaration?
int num = recur(6);
The function recur is defined as follows:
public int recur(int x)
{
if (x <= 1)
{
return 1;
}
else
{
return x + recur(x/2);
}
}
How many times is recur called in the following declaration?
int num = recur(6);
The first call is in the declaration. Because 6 > 1, it calls recur, which makes the total 2.
Next, it calls recur(6/2). Because 3 > 1, it calls recur again, which makes the total 3.
Next, it calls recur(3/2). Because it's dividing integers, this evaluates to recur(1).
Because 1 <= 1, it doesn't call recur anymore, so that total number of calls is 3.
The first call is in the declaration. Because 6 > 1, it calls recur, which makes the total 2.
Next, it calls recur(6/2). Because 3 > 1, it calls recur again, which makes the total 3.
Next, it calls recur(3/2). Because it's dividing integers, this evaluates to recur(1).
Because 1 <= 1, it doesn't call recur anymore, so that total number of calls is 3.
Compare your answer with the correct one above
What is the difference between inorder traversal of a binary search tree and a preorder traversal?
What is the difference between inorder traversal of a binary search tree and a preorder traversal?
In this case, the names help to identify the different types of traversals. In order traversal processes the binary tree "in order", meaning it will go through the left subtree, process the node, then go on to the right. Why is this in order? Because remember, a binary sort tree lists any value less than the node to the left, and any value greater to the right, so in order traversal will actually go from greatest to smallest.
Preorder traversal is the same except that it processes the root node first, hence the "pre" order.
In this case, the names help to identify the different types of traversals. In order traversal processes the binary tree "in order", meaning it will go through the left subtree, process the node, then go on to the right. Why is this in order? Because remember, a binary sort tree lists any value less than the node to the left, and any value greater to the right, so in order traversal will actually go from greatest to smallest.
Preorder traversal is the same except that it processes the root node first, hence the "pre" order.
Compare your answer with the correct one above
{1, 9, 5, 4, 2, 0, 4}
What would the set of numbers look like after four iterations of Insertion Sort?
{1, 9, 5, 4, 2, 0, 4}
What would the set of numbers look like after four iterations of Insertion Sort?
Insertion Sort is a sorting algorithm that starts at the beginning of an array and with each iteration of the array it sorts the values from smallest to largest.
Therefore, after four iterations of Insertion Sort, the first four numbers will be in order from smallest to largest.
Insertion Sort is a sorting algorithm that starts at the beginning of an array and with each iteration of the array it sorts the values from smallest to largest.
Therefore, after four iterations of Insertion Sort, the first four numbers will be in order from smallest to largest.
Compare your answer with the correct one above
Which of the following do we consider when choosing a sorting algorithm to use?
I. Space efficiency
II. Run time efficiency
III. Array size
IV. Implementation language
Which of the following do we consider when choosing a sorting algorithm to use?
I. Space efficiency
II. Run time efficiency
III. Array size
IV. Implementation language
All of the choices are important when choosing a sorting algorithm. Space and time complexity are the characteristics by which we measure the performance of an algorithm. the array size directly affects the performance of an algorithm. In addition, the language which the algorithm is written in can also affect the performance (for example, insertion sort may run faster in one language versus another, due the way the language was designed).
All of the choices are important when choosing a sorting algorithm. Space and time complexity are the characteristics by which we measure the performance of an algorithm. the array size directly affects the performance of an algorithm. In addition, the language which the algorithm is written in can also affect the performance (for example, insertion sort may run faster in one language versus another, due the way the language was designed).
Compare your answer with the correct one above
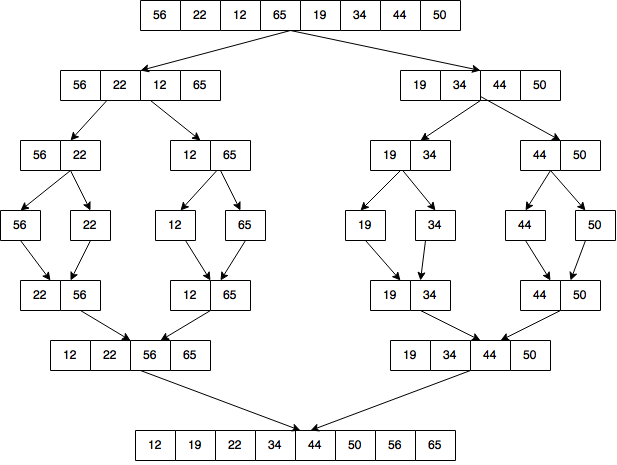
The above diagram represents what type of sorting algorithm?
The above diagram represents what type of sorting algorithm?
Mergesort consists of breaking down an unsorted list into subarrays; sorting each sub-array, and recombining the sub-arrays into larger arrays.
Mergesort consists of breaking down an unsorted list into subarrays; sorting each sub-array, and recombining the sub-arrays into larger arrays.
Compare your answer with the correct one above
How is merge sort accomplished?
How is merge sort accomplished?
In merge sort, a list is broken up into sublists containing 1 element. Each element is then compared to another element and sorted. Each 2-element group is then combined with other 2-element groups, comparing the first value of each group and deciding how to four elements. The larger group of four is compared to another group of four, until the process ends and the list is sorted.
In merge sort, a list is broken up into sublists containing 1 element. Each element is then compared to another element and sorted. Each 2-element group is then combined with other 2-element groups, comparing the first value of each group and deciding how to four elements. The larger group of four is compared to another group of four, until the process ends and the list is sorted.
Compare your answer with the correct one above
Of the choices below, what is the most efficient sorting algorithm for an unordered list where the size of the list is an odd number and the size of the list is finite?
Of the choices below, what is the most efficient sorting algorithm for an unordered list where the size of the list is an odd number and the size of the list is finite?
Mergesort is the most efficient among the choices. Both selection sort and insertion sort use O(N2) time. Bubble Sort may seem like a good answer but uses O(N2) time most of the time and can be adapted to use O(N) time however only when the list is nearly sorted, so it's a gamble. Mergesort always uses O(NlogN) time and thus is always the most efficient among the four choices.
Mergesort is the most efficient among the choices. Both selection sort and insertion sort use O(N2) time. Bubble Sort may seem like a good answer but uses O(N2) time most of the time and can be adapted to use O(N) time however only when the list is nearly sorted, so it's a gamble. Mergesort always uses O(NlogN) time and thus is always the most efficient among the four choices.
Compare your answer with the correct one above
What is the worst-case run-time of selection sort (in Big-O notation?)
What is the worst-case run-time of selection sort (in Big-O notation?)
Selection sort is comprised of outer and inner for loops that swap elements of the unsorted array into a sorted array. The largest possible number of times each loop can run is the number of elements in the array. Thus, the worst possible run time is .
Selection sort is comprised of outer and inner for loops that swap elements of the unsorted array into a sorted array. The largest possible number of times each loop can run is the number of elements in the array. Thus, the worst possible run time is
Compare your answer with the correct one above
True or False.
Selection sort is quicker than MergeSort.
True or False.
Selection sort is quicker than MergeSort.
MergeSort is has a running time of O(N). Selection sort has a running time of O(N2). Selection sort has O(N2) comparisons due to the swap in the algorithm.
MergeSort is has a running time of O(N). Selection sort has a running time of O(N2). Selection sort has O(N2) comparisons due to the swap in the algorithm.
Compare your answer with the correct one above
Which of the following code performs a multiplication by 5 of the elements of the array defined as:
int\[\]\[\] vals = new int\[50\]\[100\];
Presume that the array has been properly initialized and filled with values.
Which of the following code performs a multiplication by 5 of the elements of the array defined as:
int\[\]\[\] vals = new int\[50\]\[100\];
Presume that the array has been properly initialized and filled with values.
What we are looking for in this problem is a standard traversal of a 2D array. When you do this, you need to make sure that you iterate through both the rows and the columns. In order to do this, you first must set up a loop like:
for(int i = 0; i < vals.length;i++) {...
The value of vals.length indicates the number of rows in the 2D array.
Now, for each row, you have a certain number of columns. (A 2D array is like an "array of arrays".) Thus, for each row, you need to run through the entire set of columns for that row:
for(int j = 0; j < vals\[i\].length; j++) { ...
Notice that none of the incorrect questions use vals\[i\].length in this way. Thus, none of them iterate through the two dimensions of the array correctly.
What we are looking for in this problem is a standard traversal of a 2D array. When you do this, you need to make sure that you iterate through both the rows and the columns. In order to do this, you first must set up a loop like:
for(int i = 0; i < vals.length;i++) {...
The value of vals.length indicates the number of rows in the 2D array.
Now, for each row, you have a certain number of columns. (A 2D array is like an "array of arrays".) Thus, for each row, you need to run through the entire set of columns for that row:
for(int j = 0; j < vals\[i\].length; j++) { ...
Notice that none of the incorrect questions use vals\[i\].length in this way. Thus, none of them iterate through the two dimensions of the array correctly.
Compare your answer with the correct one above
Which of the following defines a method that successfully deletes an item from an array of integers?
Which of the following defines a method that successfully deletes an item from an array of integers?
Of course, this is an inefficient way to do such a delete, but arrays are rather "locked" data structures in that their size cannot change without a reassignment. (You could, of course keep track of the last "used" index. However, that is a different implementation, not reflected here.) The correct answer is the one that carefully goes through the original array, copying those contents into the new array skipping the one value that is not wanted.
Of course, this is an inefficient way to do such a delete, but arrays are rather "locked" data structures in that their size cannot change without a reassignment. (You could, of course keep track of the last "used" index. However, that is a different implementation, not reflected here.) The correct answer is the one that carefully goes through the original array, copying those contents into the new array skipping the one value that is not wanted.
Compare your answer with the correct one above
public static boolean remove(int\[\] arr, int val) {
boolean found = false;
int i;
for(i = 0; i < arr.length && !found; i++) {
if(arr\[i\] == val) {
found = true;
}
}
if(found) {
for(int j = i; j < arr.length;j++) {
arr\[j - 1\] = arr\[j\];
}
arr\[arr.length - 1\] = 0;
}
return found;
}
For the code above, what will be the content of the variable arr at the end of execution, if the method is called with the following values for its parameters:
arr = {3,4,4,5,17,4,3,1}
val = 4
public static boolean remove(int\[\] arr, int val) {
boolean found = false;
int i;
for(i = 0; i < arr.length && !found; i++) {
if(arr\[i\] == val) {
found = true;
}
}
if(found) {
for(int j = i; j < arr.length;j++) {
arr\[j - 1\] = arr\[j\];
}
arr\[arr.length - 1\] = 0;
}
return found;
}
For the code above, what will be the content of the variable arr at the end of execution, if the method is called with the following values for its parameters:
arr = {3,4,4,5,17,4,3,1}
val = 4
This code simulates the removal of a value from an array by shifting all of the elements after that one so that the array no longer contains the first instance of that value. So, for instance, this code takes the original array {3,4,4,5,17,4,3,1} and notices the first instance of 4: {3,**4**,4,5,17,4,3,1}. Next, it starts shifting things to the left. Thus, some of the steps will look like this:
{3,4,4,5,17,4,3,1}
{3,4,5,5,17,4,3,1}
{3,4,5,17,17,4,3,1}
...
{3,4,5,5,17,4,1,1}
Then, at the very end, it sets the last element to 0:
{3,4,5,17,4,3,1,0}
This code simulates the removal of a value from an array by shifting all of the elements after that one so that the array no longer contains the first instance of that value. So, for instance, this code takes the original array {3,4,4,5,17,4,3,1} and notices the first instance of 4: {3,**4**,4,5,17,4,3,1}. Next, it starts shifting things to the left. Thus, some of the steps will look like this:
{3,4,4,5,17,4,3,1}
{3,4,5,5,17,4,3,1}
{3,4,5,17,17,4,3,1}
...
{3,4,5,5,17,4,1,1}
Then, at the very end, it sets the last element to 0:
{3,4,5,17,4,3,1,0}
Compare your answer with the correct one above
Traverse and print out this list
List integers = new ArrayList();
integers.add(1);
integers.add(2);
integers.add(3);
Traverse and print out this list
List
integers.add(1);
integers.add(2);
integers.add(3);
Use a for loop to traverse the list. The .size() method is used for Lists as opposed to the .length method for arrays. The .get() method is used for Lists as opposed to accessing the index for arrays.
Use a for loop to traverse the list. The .size() method is used for Lists as opposed to the .length method for arrays. The .get() method is used for Lists as opposed to accessing the index for arrays.
Compare your answer with the correct one above
int\[\] arr = new int\[20\];
int x = 6,i=2;
for(int j = 0; j < x; j++) {
arr\[j\] = j * 40 + 20;
}
for(int j = x; j > i; j--) {
arr\[j\] = arr\[j - 1\];
}
arr\[i\] = 20;
for(int j = 0; j < x; j++) {
System.out.print(arr\[j\] + " ");
}
What is the output for the code above?
int\[\] arr = new int\[20\];
int x = 6,i=2;
for(int j = 0; j < x; j++) {
arr\[j\] = j * 40 + 20;
}
for(int j = x; j > i; j--) {
arr\[j\] = arr\[j - 1\];
}
arr\[i\] = 20;
for(int j = 0; j < x; j++) {
System.out.print(arr\[j\] + " ");
}
What is the output for the code above?
It is easiest to understand this by a bit of code parsing:
First, there is the loop: for(int j = 0; j < x; j++) { // ...
This will fill the array with 20 + 0, 20 + 40, 20 + 80, ... Thus, it will be:
20, 60, 100, 140, 180, 220
Next, there is the array: for(int j = x; j > i; j--) { // ...
This basically shifts everything after index i backward by 1. Thus you have:
20, 60, 100,100, 140, 180, 220
Next, you set arr\[2\] equal to 20:
20, 60, 20,100, 140, 180, 220
Finally you output each of the first 6 elements. Be careful here. Notice that it is from j = 0 to x - 1!
Thus, the answer is:
20 60 20 100 140 180
This algorithm basically implements a simple kind of array deletion.
It is easiest to understand this by a bit of code parsing:
First, there is the loop: for(int j = 0; j < x; j++) { // ...
This will fill the array with 20 + 0, 20 + 40, 20 + 80, ... Thus, it will be:
20, 60, 100, 140, 180, 220
Next, there is the array: for(int j = x; j > i; j--) { // ...
This basically shifts everything after index i backward by 1. Thus you have:
20, 60, 100,100, 140, 180, 220
Next, you set arr\[2\] equal to 20:
20, 60, 20,100, 140, 180, 220
Finally you output each of the first 6 elements. Be careful here. Notice that it is from j = 0 to x - 1!
Thus, the answer is:
20 60 20 100 140 180
This algorithm basically implements a simple kind of array deletion.
Compare your answer with the correct one above
public static int[] doWork(int[] arr, int val,int index) {
int[] ret = new int[arr.length + 1];
for(int i = 0; i < index; i++) {
ret[i] = arr[i];
}
ret[index] = val;
for(int i = index + 1; i < ret.length; i++) {
ret[i] = arr[i - 1];
}
return ret;
}
What does the code above perform?
public static int[] doWork(int[] arr, int val,int index) {
int[] ret = new int[arr.length + 1];
for(int i = 0; i < index; i++) {
ret[i] = arr[i];
}
ret[index] = val;
for(int i = index + 1; i < ret.length; i++) {
ret[i] = arr[i - 1];
}
return ret;
}
What does the code above perform?
A quesiton like this is most easily understood by doing a careful reading of the code in question. Let's consider each major section of code:
int[] ret = new int[arr.length + 1];
This line of code creates a new array, one that is 1 longer than the array arr.
for(int i = 0; i < index; i++) . . .
This loop copies into ret the values of arr up to index - 1.
(This is because of the i < index condition)
Then, the code stores the value val in ret[index]
_for(int i = index + 1; i < ret.length; i++) . . ._
It then finishes copying the values into ret.
Thus, what this does is insert a value into the original array arr, returning the new array that is one size larger. (This is necessary because of the static sizing of arrays in Java.)
A quesiton like this is most easily understood by doing a careful reading of the code in question. Let's consider each major section of code:
int[] ret = new int[arr.length + 1];
This line of code creates a new array, one that is 1 longer than the array arr.
for(int i = 0; i < index; i++) . . .
This loop copies into ret the values of arr up to index - 1.
(This is because of the i < index condition)
Then, the code stores the value val in ret[index]
_for(int i = index + 1; i < ret.length; i++) . . ._
It then finishes copying the values into ret.
Thus, what this does is insert a value into the original array arr, returning the new array that is one size larger. (This is necessary because of the static sizing of arrays in Java.)
Compare your answer with the correct one above
public static int[] doWork(int[] arr, int val,int index) {
int[] ret = new int[arr.length + 1];
for(int i = 0; i < index; i++) {
ret[i] = arr[i];
}
ret[index] = val;
for(int i = index + 1; i < ret.length; i++) {
ret[i] = arr[i - 1];
}
return ret;
}
Which of the following is a possible error in the first loop in code above?
I. The array arr might be indexed out of bounds.
II. The array ret might be indexed out of bounds.
III. A null pointer exception might occur.
public static int[] doWork(int[] arr, int val,int index) {
int[] ret = new int[arr.length + 1];
for(int i = 0; i < index; i++) {
ret[i] = arr[i];
}
ret[index] = val;
for(int i = index + 1; i < ret.length; i++) {
ret[i] = arr[i - 1];
}
return ret;
}
Which of the following is a possible error in the first loop in code above?
I. The array arr might be indexed out of bounds.
II. The array ret might be indexed out of bounds.
III. A null pointer exception might occur.
The most obvious possible error is that the array arr might be a null value. You need to check for these kinds of values before using the variables. (If you do arr[0] on a null value, an exception will be thrown.) In addition, it is possible that a value for index might be given that is too large. Consider if index = 100 but arr is only 4 elements long. Then, you will have ret be a 5 value array. When the first loop starts to run, you will go all the way to 99 (or at least attempt to do so) for the index value i_; h_owever, once you get to ret[4] = arr[4], there will be an out of bounds error on arr, which only has indices 0, 1, 2, and 3. Of course, there could be other problems later on with ret, but the question only asks about this first loop.
The most obvious possible error is that the array arr might be a null value. You need to check for these kinds of values before using the variables. (If you do arr[0] on a null value, an exception will be thrown.) In addition, it is possible that a value for index might be given that is too large. Consider if index = 100 but arr is only 4 elements long. Then, you will have ret be a 5 value array. When the first loop starts to run, you will go all the way to 99 (or at least attempt to do so) for the index value i_; h_owever, once you get to ret[4] = arr[4], there will be an out of bounds error on arr, which only has indices 0, 1, 2, and 3. Of course, there could be other problems later on with ret, but the question only asks about this first loop.
Compare your answer with the correct one above